j1|中科大何力新教授:当量子力学遇见AI——深度学习在超算平台上模拟量子多体问题( 四 )
但是这个模型和一般的机器学习算法有所差异。第一,它需要极高的精度,我们需要比其他方法要求高至少2个量级的精度。其原因是量子态的求解精度需求极高,微小的误差将对基态解产生巨大影响。此外,系统中可能存在多个局部最优点,若我们用普通方法进行优化,则可能陷入局域极值中。
为了解决这个问题,我们使用SR方法进行解决。在机器学习中我们常称之为自然梯度法。为了更新网络参数,我们需要求解能量对参数的多个梯度,为了计算梯度相,我们需要进行求导,并求解关联矩阵的预处理,加速收敛。

文章插图
这里的计算热点包括马尔可夫采样。因为我们需要计算关联矩阵,需要50万sweep的自旋样本,每个sweep都需要对所有网格进行翻转。但是在sweep之间是不需要进行求导和反向传播的,我们只需要正向执行,并在全部sweep做完后进行反向传播,以此降低通讯时间占比,以及计算量。
另一个计算热点是SR优化方法。在SR算法中一个重要步骤是计算大的关联矩阵,然后求解线性方程组。具体哪部分的耗时是最严重的,其实是由模型参数大小所决定的。如果系统越大,采样越耗时,参数越多,SR方法的耗时越大。
文章插图
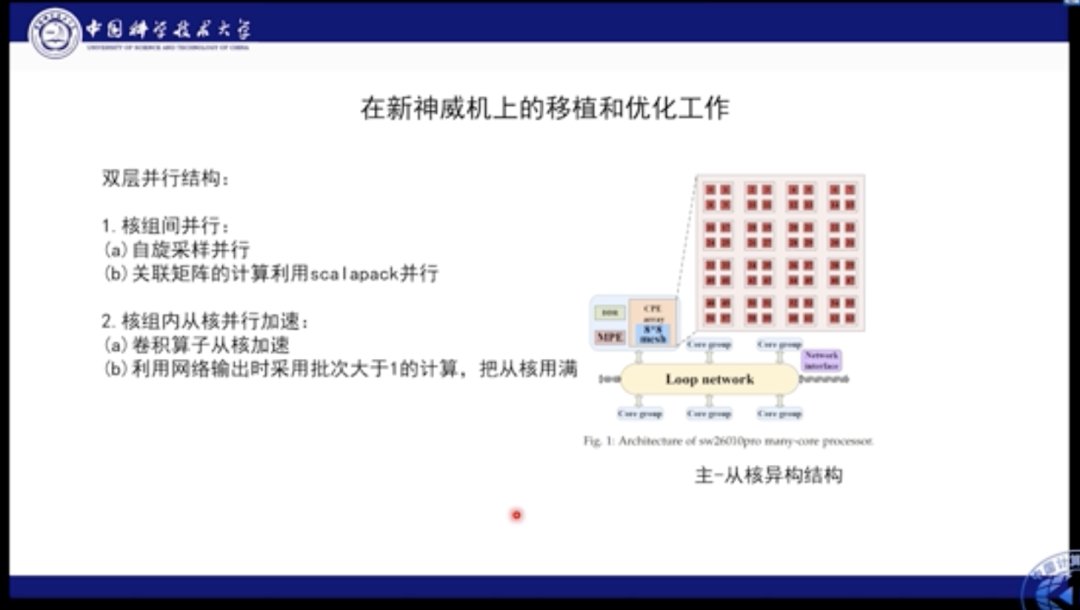
我们分别在自己的机器以及新一代的神威机上进行了验证和部署。神威机具有异构的结构,其NPI处于核组之间,因此有64个组合。在核组级别上的并行本质是线程并行。神威机的异构结构很适合此类应用,因此为了最大化利用神威机的能力,我们针对神威机的特点和应用特点设计了双层并行方案。首先在核组之间的并行被用作自旋采样,即每个自旋部署在不同的核组之上进行独立采样。在求解线性方程组的时候,会使用ScaLAPACK进行计算划分。在并行内部,我们使用卷积算子从核加速,并利用网络输出时采用批次>1的计算,将从核的计算性能妥善利用。
文章插图
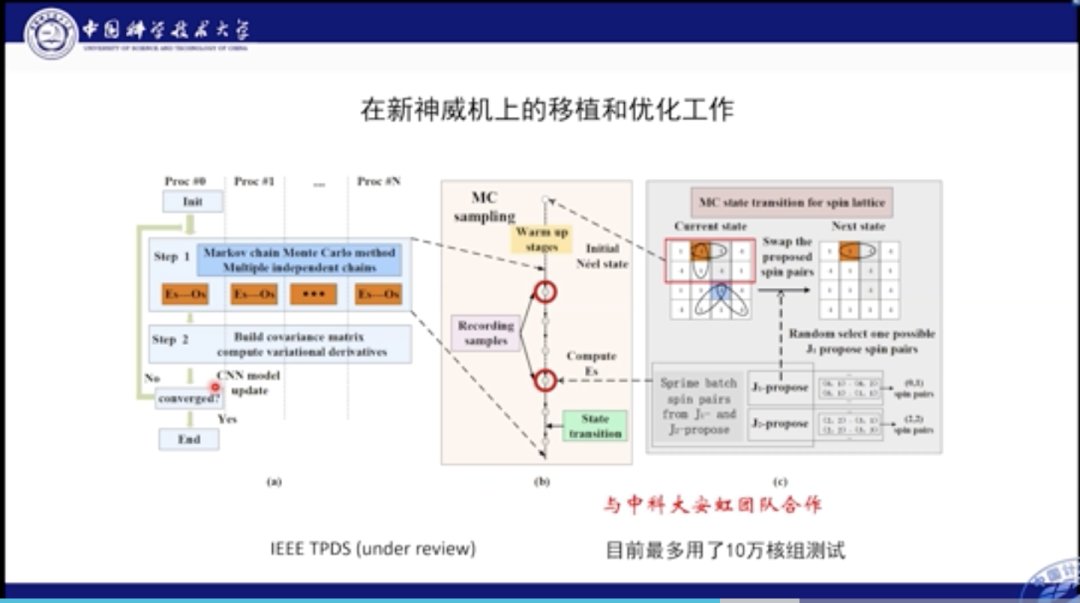
这是我们的程序在新的神威机上的移植和优化的示意图全览。可以看到在不同的核组之间我们进行了单独独立的采样;采样后将其收集并计算关联矩阵,并求导更新参数。这项工作最大利用了10万核组测试。
文章插图
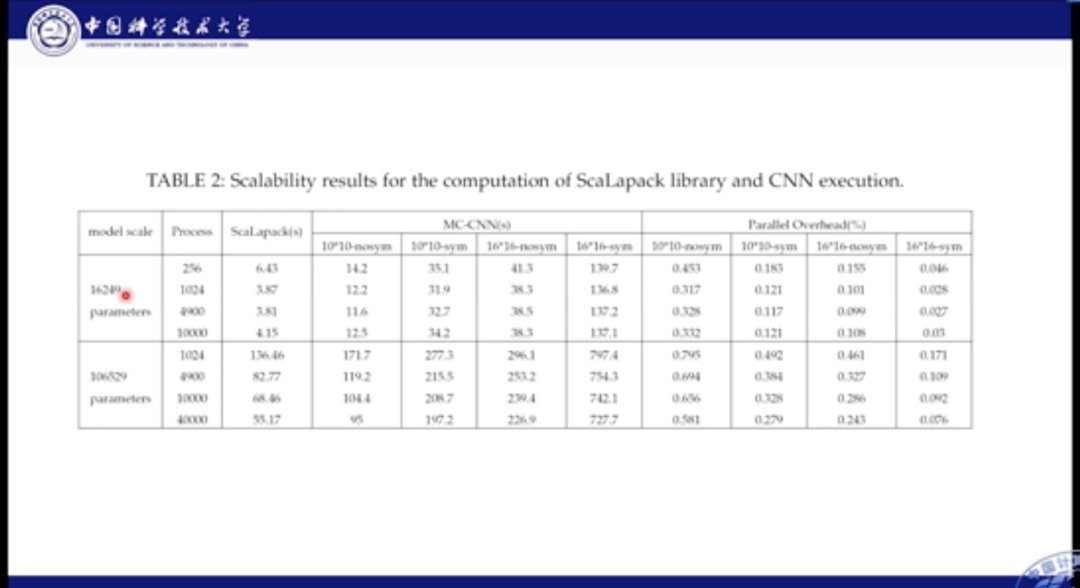
在性能表现方面,我们对比各个主机的用时结果。从上图中我们可以看到,我们分别比较了16000个参数,和10万个参数的场景。不论参数量如何,其主要的计算时间还是集中在前向计算部分,SR优化的占比只有1/4左右。
文章插图
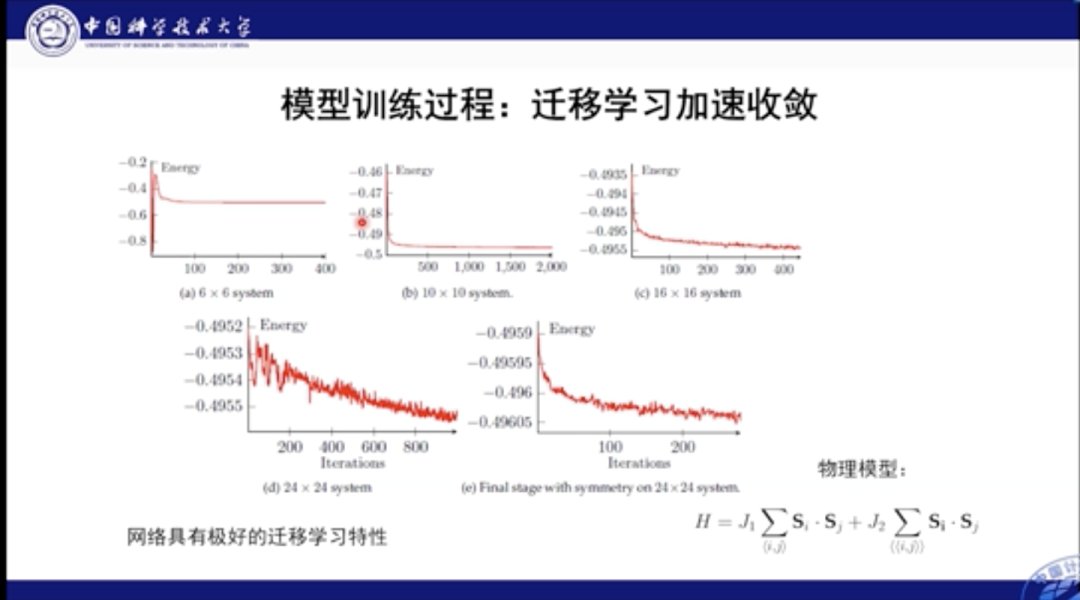
本工作的另一个优点在于其可迁移性极高。我们首先可以在较小的神经网络中进行学习,而后将其扩展到体积大的网络中。在实践中,迁移后通常只需要几百步便可以使大网络收敛,这无疑加速了模型的训练和应用。
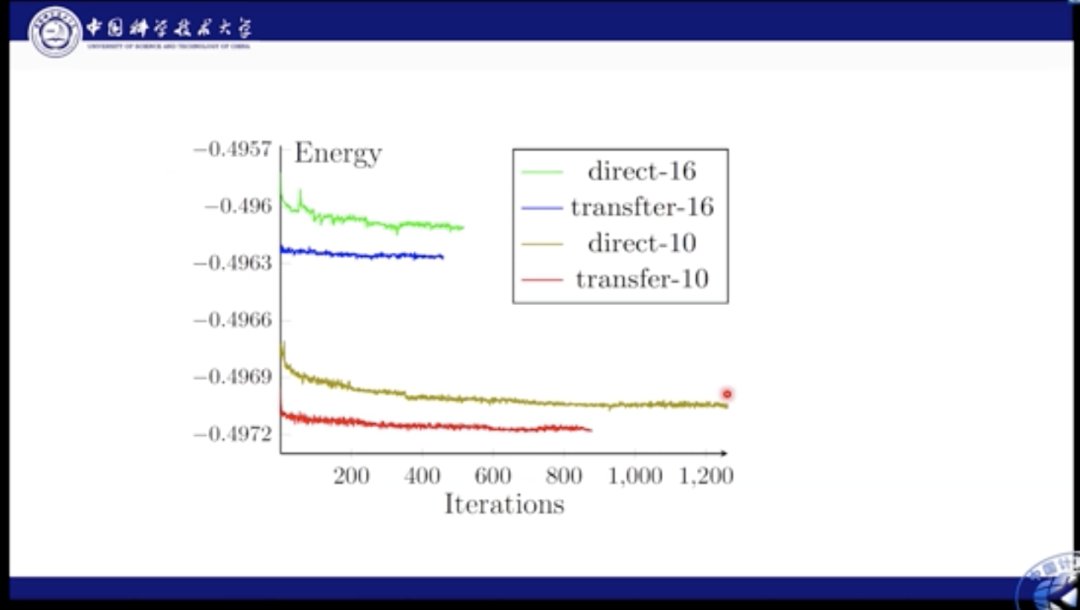
文章插图
这里我们对比了性能。绿色和棕色线都是直接学习的结果,蓝色和红色是迁移的结果。通过图中结果我们知道,如果使用直接学习,则网络很难收敛到最佳结果,而迁移则极大加快了这个最优化的过程。

文章插图
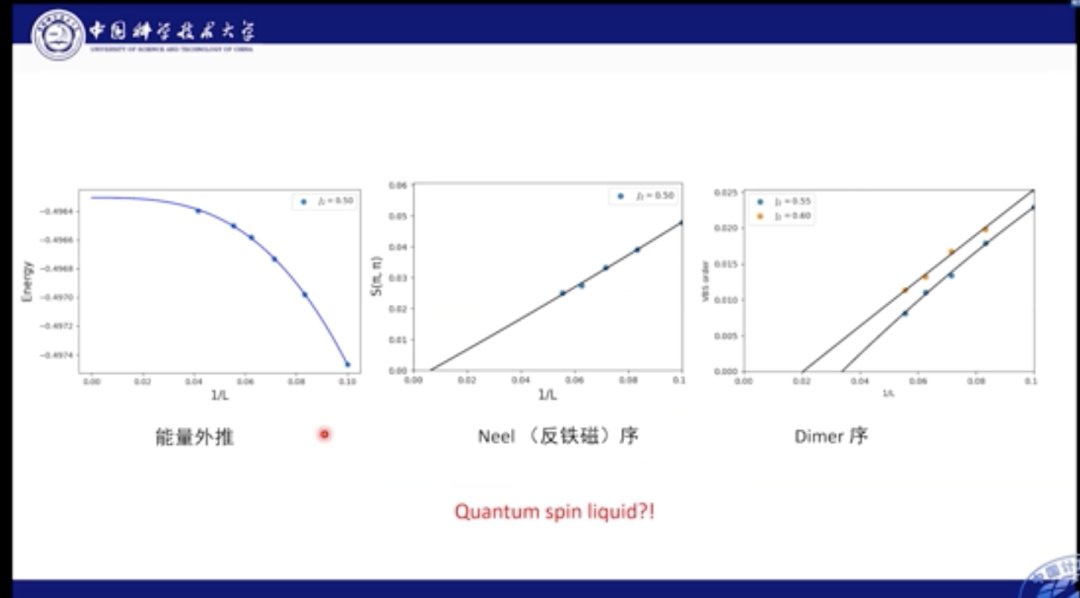
文章插图
我们也分析了基态能量部分的外推结果,经过计算发现,能量在网格达到24×24后便逐渐收敛,我们也对多种磁序进行外推,比如Dimer序和反铁磁序。结果发现,系统在中间区域的基态是自旋液体相。
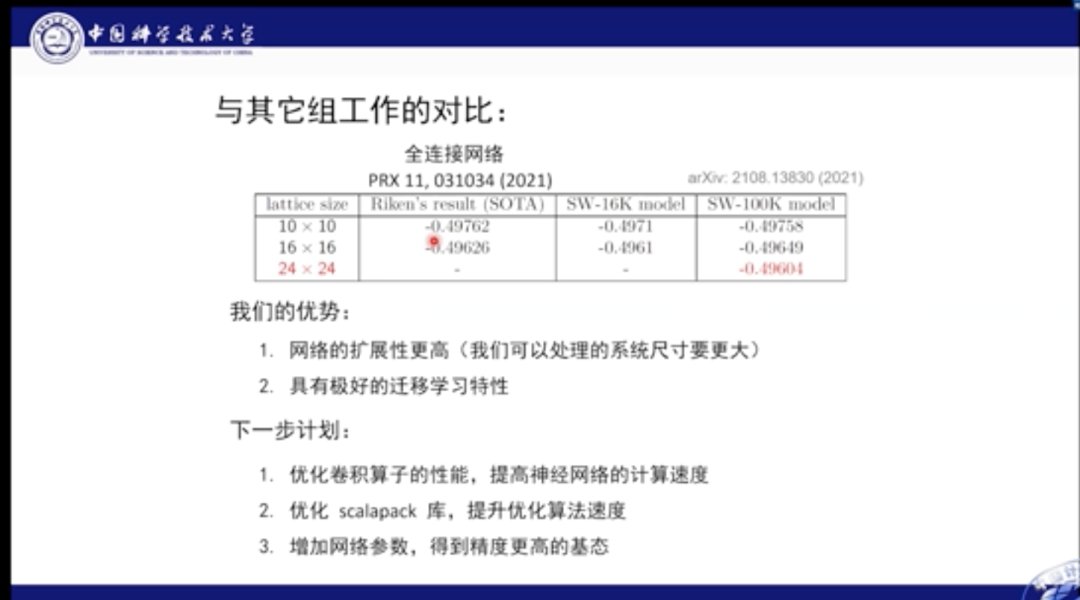
文章插图
与之前的最佳结果对比,我们的优势在于,网络的扩展性更高,也就是可以处理的系统尺寸更大,具有极好的迁移学习特征。
在下一步工作中,我们将继续进行相关研究,主要优化卷积算子的性能,提高神经网络的计算速度;优化ScaLAPACK库,提升优化算法的速度;增加网络参数,得到精度更高的基态。
- 高通骁龙|谷歌希望学校教授Chromebook维修课程
- 联想|为何大V们不愿谈联想事件?其实态度早已明确,只有储教授心急了
- 安全|浙江大学求是讲席教授任奎:隐私计算的前沿进展
- 安兔兔|美国教授:这些顶尖技术都得从美国进口,还请不要过于自信!
- 基站|英国教授:中国人太可怕,全民已经开始普及5G,我们却还在烧基站
- G上海长征医院萧毅教授:医学影像 图像
- 5G|比5G更让美国头疼?关键领域已取得重大突破,中科大这回功劳不小
- 联想|一个王教授,发视频称为什么大家只喷联想,不喷桓大
- realme|realme GT2被清华教授点赞:这才是真正的环保
- 联想|重量级人物发声,揭开联想盖子的教授被解聘,柳传志真的不简单