数据中台:从0到1打造一个离线推荐系统( 二 )
GBDT的优点是自动挖掘用户的特征,得到最佳的特征组合,省去构建特征工程的烦琐工作。
逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种,通过历史数据的表现对未来结果发生的概率进行预测;例如,我们可以将用户喜欢某商品的概率设置为因变量,将用户的特征属性,例如性别,年龄,注册时间、偏好品类等设置为自变量。根据特征属性预测用户对某件商品喜欢的的概率。
在实际项目中,我们可以找产品线的产品/运营人员一起讨论下推荐方案。他们对业务更了解,可能会提出一些好的建议;比如笔者在构建推荐系统过程中,同公司的产品/运营人员就提出了以下建议。
1)笔者所在公司的电商产品定位快时尚女装,所以几乎每天都会新品上架,而新品上架7天后就基本没有货了,这种情况给推荐算法带来很大挑战;而且新款一般不会有太多的交易数据,无论是基于物品的协同过滤算法,还是基于用户的协同过滤算法只会推荐很少新款。
经过与产品/运营人员的讨论,我们决定为商品打上“新款”或“旧款”标识。因为每一件商品都放在某个专场内,而专场都有开始时间和结束时间。如果商品所在的专场没有结束,那么我们会给商品打上“新款”标识;如果商品所在的专场已经结束,那么我们会给商品打上“旧款”标识。如此一来,只要提高基于内容的推荐算法中“新款”标签权重,这样就能更好地推荐新款商品。
2)为了应对实际的业务场景,需要增加一些过滤条件。比如对于下架的商品、用户若干天内购买过的商品,我们需要在提交给用户的最终推荐结果中将之去除;对于一些退货率比较高的商品,我们设置了一个阀值,如果商品的退货率超过该阀值,那么这些商品也会在推荐列表中被统一去除。
3)需要考虑商品的上架时间和用户访问高峰期因素。笔者所在公司的电商平台一般都是在早晨10点左右上架一次商品,在下午18点左右也会上架一次商品,而中午12点左右和晚上20点左右是用户访问的高峰期,也是用户下单的高峰期。
如果离线推荐系统的计算引擎只在晚上计算,那么在早晨10点左右和下午18点左右上架的商品,大部分都不能被推荐出来,这就需要调整离线推荐系统的计算调度;首先在中午12点左右进行一次计算,保证在上午10点左右上架的新品都能出现在用户的推荐列表中,然后在下午19左右进行一次计算,保证在18点左右上架的新品也能出现在下一次用户访问高峰期的推荐列表中。
三、离线推荐系统开发过程接下来,笔者从工程角度讲一下应该如何搭建推荐系统。
1)首先需要数据开发工程师根据推荐算法的需要准备几类数据。
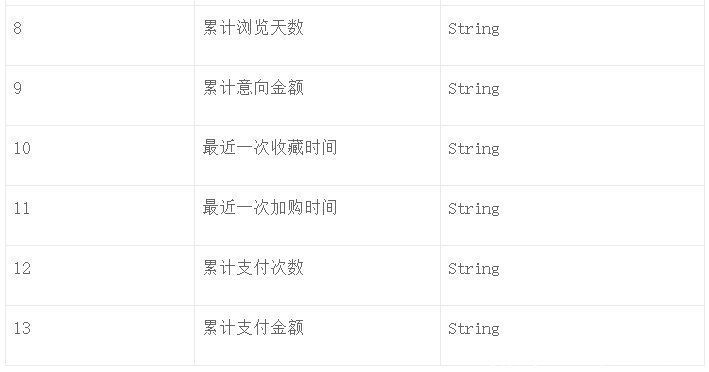
第一类是用户的基础数据,如表1-1所示,此类数据可以用来挖掘用户的特征。

文章插图
文章插图
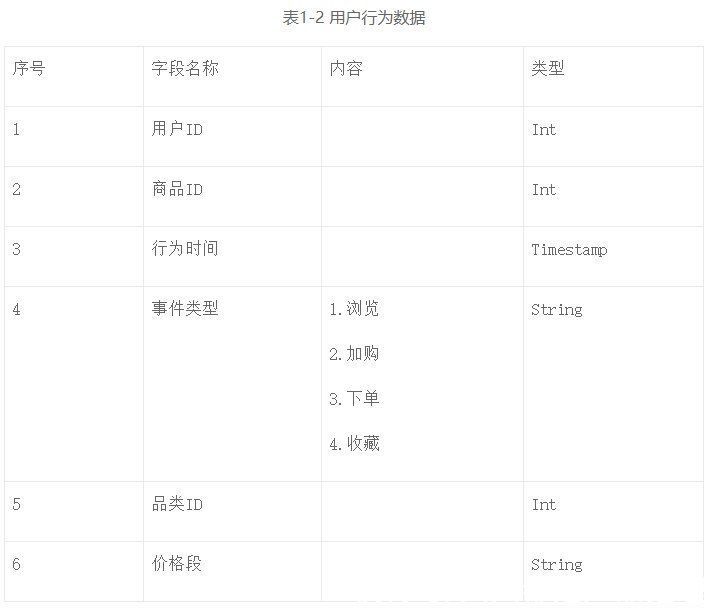
第二类是用户行为数据,如表1-2所示,比如用户在什么时间对商品有浏览、加购、下单等行为。此类数据是召回算法的基础支撑数据。
文章插图
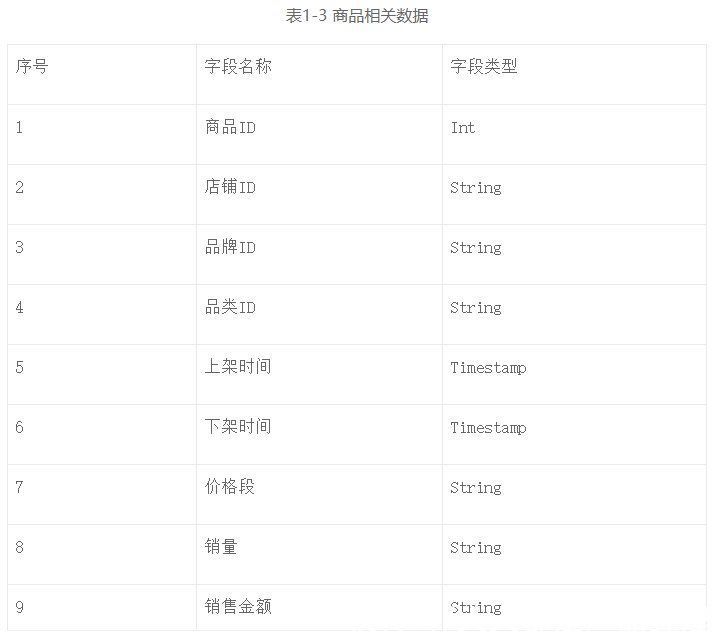
第三类是商品相关的数据,如表1-3所示,比如商品的品类、是否上/下架等基础信息。此类数据可以让算法工程师快速获得商品的相关信息。
文章插图
当算法工程师和数据开发工程师按照召回算法和排序算法的规则完成开发后,就会形成最终用户的推荐结果,一般存储在MySQL等关系型数据库中,通过接口对外提供服务。
每个用户获得的最终推荐结果的参数如下:
- 用户ID:用户的唯一标识。
- 商品ID:商品唯一标识。
- 召回算法ID:召回算法的唯一标识,用于统计召回算法的效果。
- 点击率:用户点击的概率,一般是取值在0和1之间的小数。
- 计算时间:产生推荐结果的时间,一般存储近几次的计算结果。
- 优派|美国很满意:150多家芯片厂商,都“自愿”提交了详细数据
- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 量子计算|从微商到直播,一个顶流江湖的兴衰
- 何树山|合肥国际互联网数据专用通道开通
- 互联互通|从3999跳水至2399,小米11加速退场,你还选择骁龙870吗?
- Python|联想真的没有问题?中国院士公布数据,胡锡进改变立场
- 目标|目标用户从哪来?
- 叮咚|从商品采购到商品开发,叮咚买菜打造生态型供应链体系
- 马云|媒体采访马云:如此富有为何从不“花天酒地”?马云回答引人深思
- 龚文祥|从微商到直播,一个顶流江湖的兴衰